I'd always been interested in testing other forms of content on Google, and so had always wanted to play around with getting different content indexed by Google - just for fun if more than anything.
I'd noticed a while back that Google will indeed index Google Sheets - and that's probably no surprise to hear. Just searching for a a phrase like "wedding planner spreadsheet" will yield Google sheets results with publicly available sheets based on planning a wedding.
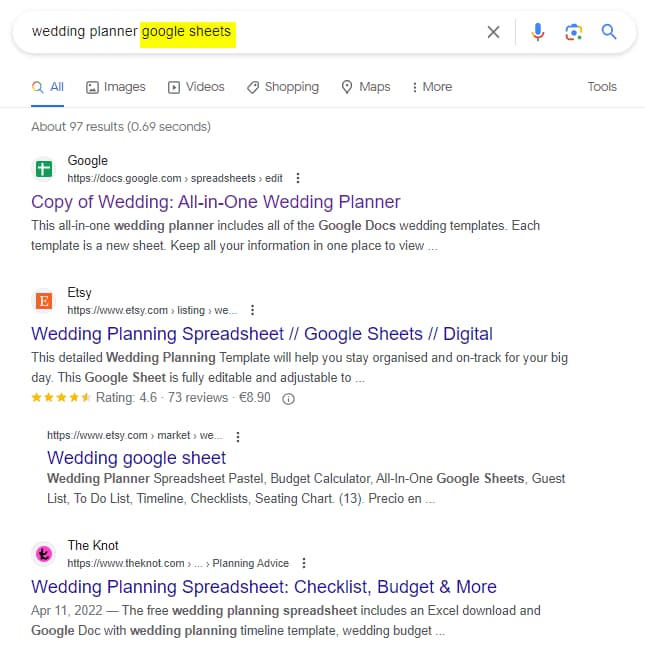
There are many other sheets indexed by Google (approximately 190,000 results to be precise) but I wanted to learn a bit more about the intricacies of indexing these files from a search engine point of view.
Testing indexability of Sheets with Search Console
I remembered that Search Console reports on the final endpoint of any URL you share within the tool, so for example if you add a redirect pointing to a Google Sheet URL, by inspecting the URL of your original page Search Console will actually report on that final URL (they don't mention the redirect which I find frustrating especially if you're trying to diagnose something that's going on - but that's a story for another day).
So - it's easy to test if a Google Sheet is indeed indexable by creating that redirect and inspecting the page.
I created a 302 redirect from https://matttutt.me/google-sheets/ that points to the Google sheet I'd setup, allowing me to see how Google fetches/renders the sheet itself.
When I did this the result I got back was that the page was not indexable - which kind of surprised me.
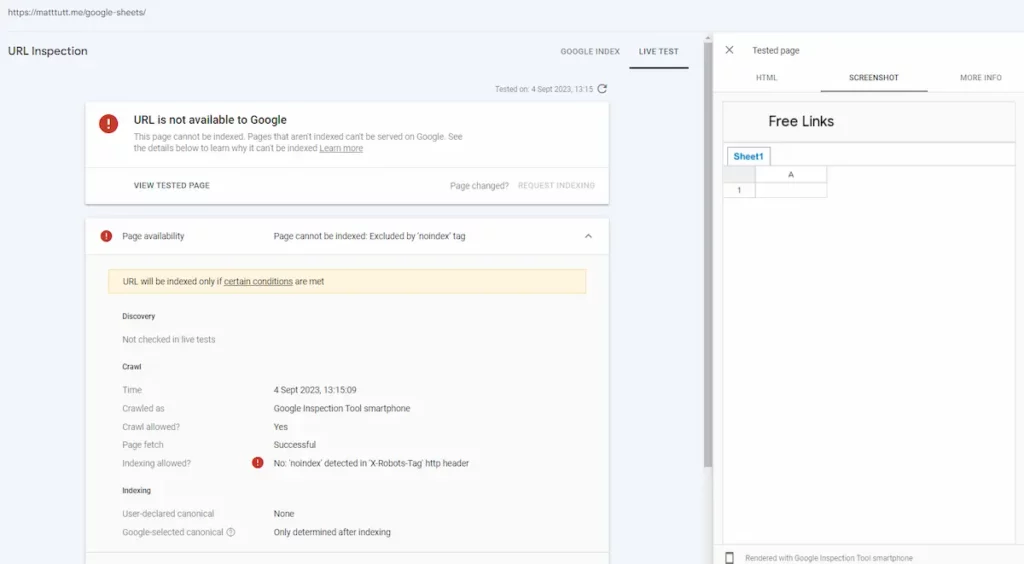
I'd checked that the Sheet had been made publicly available and tried adding some filler content to the sheet itself, but still the GSC test returned the noindex.
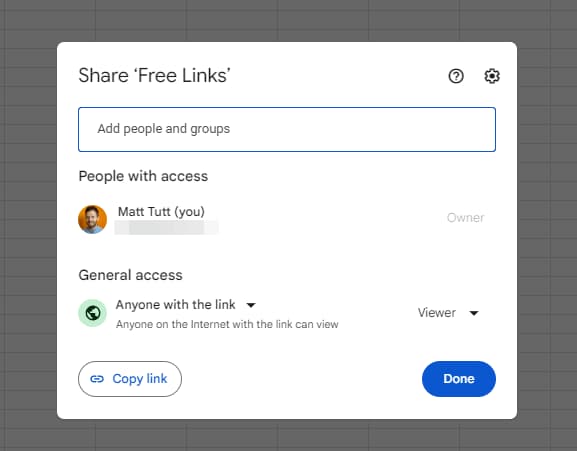
This made me think that perhaps there's some kind of requirement to unblock or remove this noindex - and so in my mind I had a few potential scenarios:
1 - Freshness of the spreadsheet ⌛
If the sheet has only just been created (literally a few minutes ago) perhaps it's not eligible for indexing, and that I'd have to wait a certain period of time. I doubted this but kept it in the back of my mind.
I did re-test the page after 24 hours but still had the same response - maybe I'd need to wait longer?
2 - Number of views of the spreadsheet 🔢
I'm not one for tin-foil theories but I did seriously consider this. If you think of the number of spreadsheets that get created on a daily basis which have been made shareable, Google must only index a very small number of those. And maybe "sheet views" is a way to control the noindex - with a certain threshold required before the noindex is lifted.
Google clearly knows how many people open a spreadsheet - you can even see this in realtime, with the Google account display pictures that pop-up to the top-right corner of any sheet when others are active within it.

So could the popularity of the sheet actually be the reason a sheet becomes indexable?
3 - Number* of links pointing to the spreadsheet 🔗
I'd find this one hard to accept because it would be very easy to abuse, simply by spamming the URL anywhere on the web. And surely that itself wouldn't have an impact on indexability.
But this could be a strong possibility - that unless a sheet has been shared publicly on the web, perhaps that would prevent Google making it indexable.
To clarify - this test wasn't about getting Google Sheets to rank organically, it was more to see what makes them indexable - having the option of being included in the SERPS.
*In the above I refer to number of links - but it could also be possible that there is no set threshold, and that all is required is a link itself (how else would Google crawl it otherwise?).
4 - That this is some kind of temporary bug / glitch in the Matrix
After a fair bit of algorithmic navel-gazing something hit me - what if this was all just some kind of temporary bug, and in a few hours/days it'll all be resolved and no-one will even believe me that this was happening? 😰 (as you can imagine, I really hoped it wasn't just a bug).
Side note here that I later added a link to the /google-sheets/ redirect in the footer of my website so that Google found fairly strong internal links pointing to the page, in a bid to "test" whether that was going to help get the sheet indexed.

Further Research on Google Sheets in the SERPS
What I also found interesting is that when making implicit queries on Google with the "Google sheets" modifier, Google is only serving me 1 result per the docs.google.com domain.
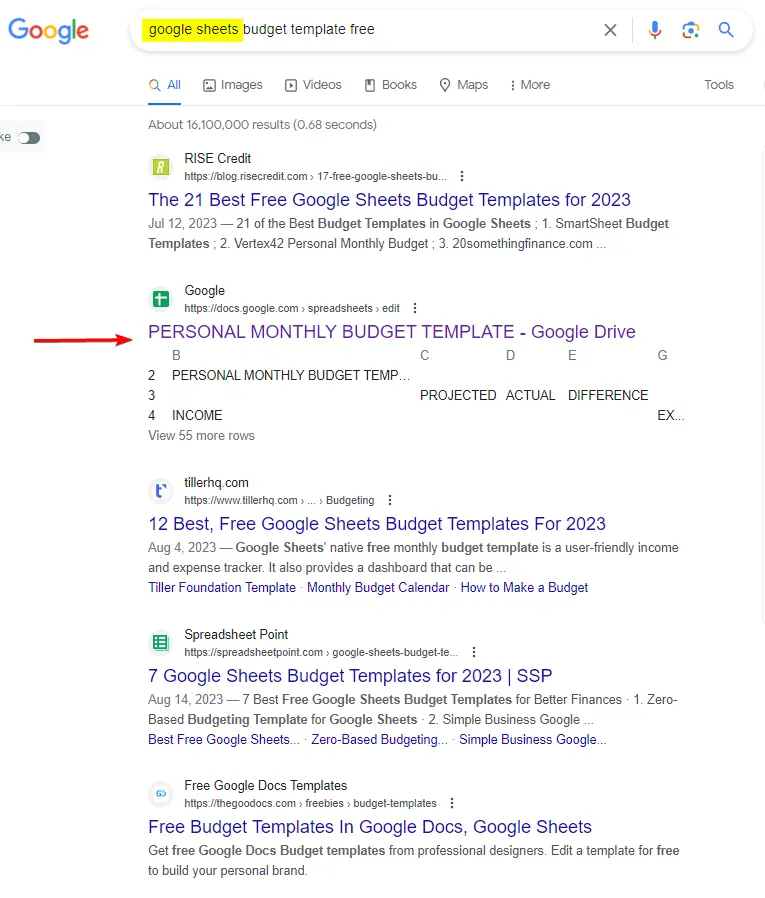
This is as if Google either knows it's not a good experience to serve multiple pages from the same domain for this kind of query, or because it has some kind of mechanism in place to prevent multiple results from the same domain.
I don't think the second is true across other "brand" specific SERPS, for example when searching "drugs Vice" - I get many pages returned from the Vice publication, aka people looking for stories about drugs published by Vice - and that makes sense.
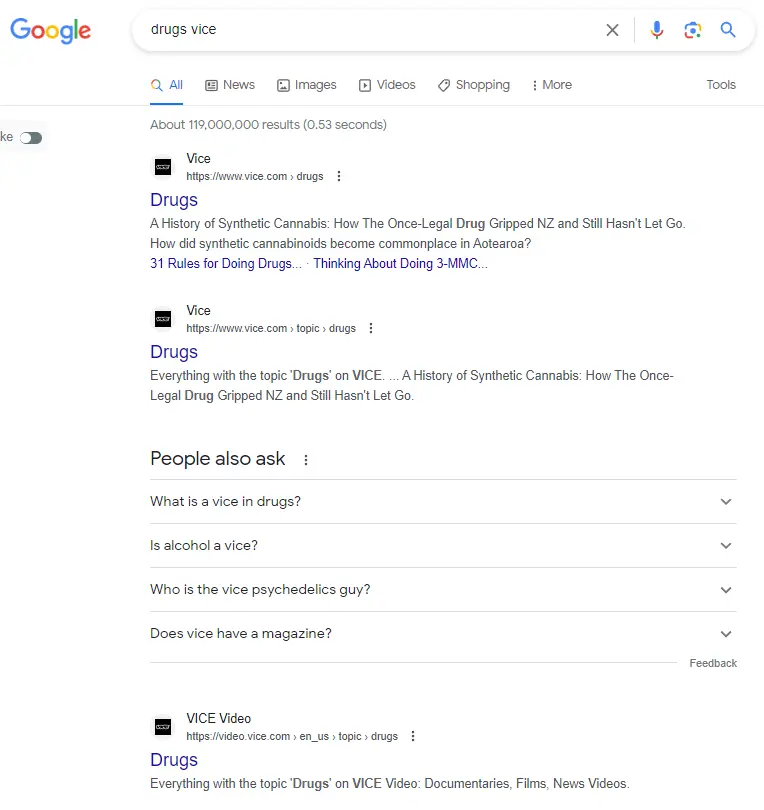
So it's weird (strange?) that when searching for "X + Google sheets" I'm limited to seeing 1 result per domain.
This has strayed somewhat from the original topic - so let's get back to what makes a Sheet indexable.
Assessing an Indexed Sheet vs an Unindexable Sheet
This was a simple test to run - I took the sheet I'd created (which was not indexable) and I checked for the HTTP response headers from Googlebot, using the Mobile Friendly Test tool.
I then took an indexed sheet I found on Google and I ran the same test, taking note of the HTTP response headers.
I put the through responses through DiffChecker and this was the response:
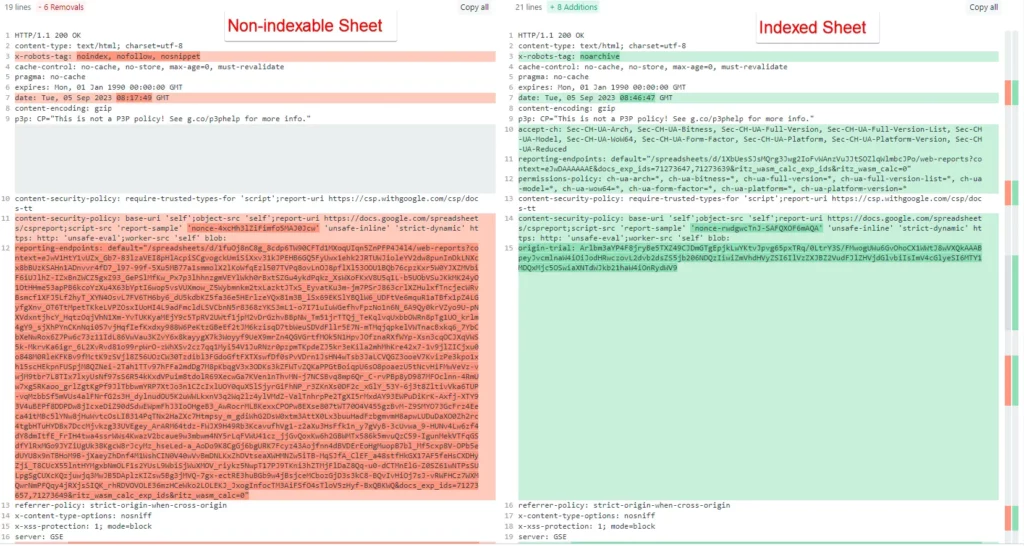
From the response we can see the differences on line 3 of the x-robots-tag, where the noindex directive and nofollow directives are both lifted (does this mean links within an indexable spreadsheet pass value to the URL's they point to?😏).
There are some other big omissions and changes - but it's hard to tell much else from the above, apart from confirming the lifting of the noindex directive.
What other SEO's think is going on - what makes Google Sheets indexable?
As you can probably tell, around about this point in the proceedings I realised that I'm going to struggle to get to the bottom of this conundrum all by myself.
That's why I decided to ask around the SEO community, fairly secretly, to see if anyone else knew what might be going on.
I was careful not to share too much publicly, as I wanted to figure out the answers right here in this blog post, like some kind of immense SEO exclusive - if at all possible.
I'm very vain and egotistical like that.
Alexander Außermayr
Maybe the spreadsheet will only be indexed if the content has some kind of "value" to it.
But also, maybe Google Spreadsheet webserver just needs some time to refresh the x-robots headers or something similar.
Maybe also the number of backlinks have an impact? The ulterior motive of Googlebot could be: "The document is publicly linked and it is publicly accessible. Maybe it's relevant for the index?"
Alexander does SEO, CRO & Web Analytics at https://aussermayr.com/

Navneet Kaur
I think that Google mostly index the Google docs/sheets that are included in some published post or somehow connected to a website.
Google index them in a way similar to indexing other webpages. However, I did find a few sheets which were not linked anywhere but were still indexed.
Google has announced in the past that they'll only crawl the Google Sheets which are published as webpage and will not crawl the sheets with share option of "anyone with the link on internet". But looks like this is not the case.
I feel that the crawlers are accidently indexing the drive documents that looks like quality content to them, just like indexing the web pages.
Almost all of the Google spreadsheets available in SERP have lots of data which shows that Google is not indexing thin pages here also.
Navneet does Technical SEO at https://thenavneet.com/

Other Comments via Social Media
That URL redirects, so it's not the Google Sheet that's not indexable; it's that specific URL. GSC is telling you the noindex is in the HTTP header.
— Lidia Infante (@LidiaInfanteM) September 11, 2023
Yes, all Google Sheets are noindexed by default, unless you publish them to the web using this ⬇️ pic.twitter.com/d73nmc0k51
wondering if this is a other people do not crawl our sheets, but we will share them if you let us - so Google have a our stuff, we do differently, we set the rules approach.
— Gerry White SEO geek (@dergal) September 11, 2023
Patrick Stox
I actually went and checked. The base links are indexable.
These 302 redirect, but a 302 keeps the original URL indexed and consolidates signals there.
You end up on some /edit URL which is noindex.
Likely the ones being indexed are being linked to without the /edit on the URL is all, but I haven't checked that.
Some only go through one redirect hop, so if they link to the base sheet that can be indexed with or without /.
Base redirects to / that redirects to add edit.
So, only the version of the URL with edit is noindex.

Patrick does Technical SEO at Ahrefs
Mystery Solved 🎉
So for those who have been paying attention, you will have by now realised what was happening, and chances are you probably feel a bit cheated 😬
It might be along the lines of "bloody hell why did I just commit 15 minutes to reading this blog post when I could have been doing something more meaningful to drive traffic to one of my client websites?!"
Well hopefully you aren't too angry, and you'll have realised how frustrating it can be that Google's testing tools fail to tell you when a redirect is taking place 😑
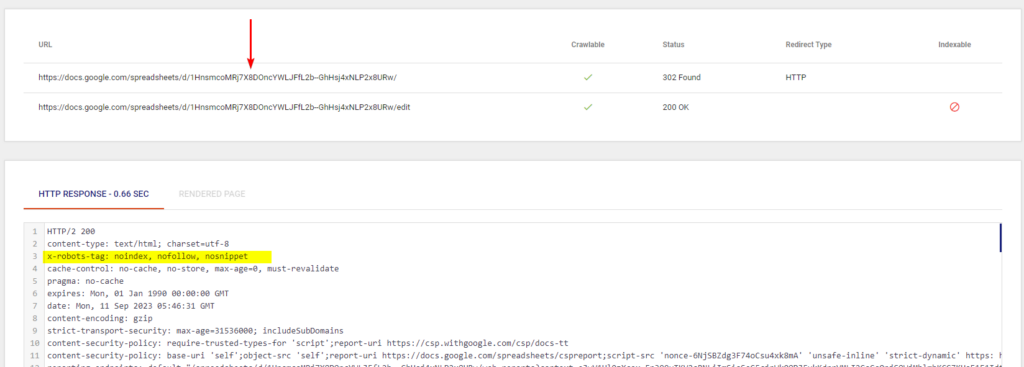
To recap for those who may have missed it - Patrick spotted the issue very quickly (and Lidia Infante pretty much solved it too later on Twitter/X).
The spreadsheet URL I was sharing actually 302's to a version with /edit appended to the end.
It is this /edit version of the sheet which has the noindex tag in the x robots header.
So, the original sheet URL will be indexable (this is an assumption as it's hard to know this) but the SEO tools used to diagnose this report on the final end point URL.
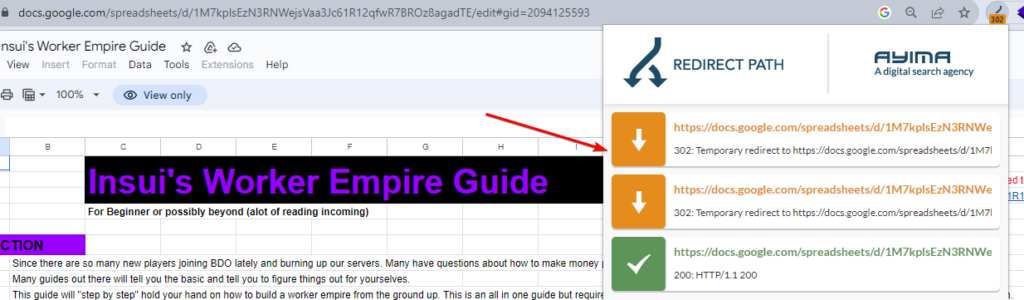
Outside of Google's Mobile Friendly Tester, and Google Search Console's Inspect URL tool, Merkle have a great range of technical SEO tools, and using their Fetch and Render tool it's clear to see the 302 redirect taking place:
An Apology 🙏
I'd like to apologise to Alexander and Navneet, two great SEO's who kindly shared quotes for this article - they wouldn't have spotted the error during my research, they were simply sharing quotes on why Google might noindex sheets by default - the brief I'd shared with them.
Also thanks to anyone on social media (Twitter/X) who gave it a go including SEO consultant Lidia Infante who pretty much solved it in the first part of her tweet (scroll up to see what she said).
That apology is extended to anyone who feels a bit cheated by this article. I could have deleted it and not published anything (really, there's not a lot to say) but because of the time I'd spent on this AND the fact I'd involved other people, I wanted to see it through.
My biggest hope is that someone reading this will remember my mistake and won't repeat it! This is that testing tools often follow redirects and report on "final destination" URLs.
My secondary hope is that I can pull out something more meaningful from this exercise (for example, seeing if Googlebot could find and crawl a link that was embedded within a Google sheet) 🤓 - but let's save that question for another day.