[Editors note - I've re-published the original contents of the PDF below, and then included a part 2 with an update on my findings].
This is one I’ve been meaning to try out for a while but kept putting off. There’s a big chance it won’t work, but I figured there’s no harm in trying, right?! 🤷♂️
(To clarify - please don’t publicly humiliate me with all the holes in my experiment).
So - what are you doing now Matt? 🤦
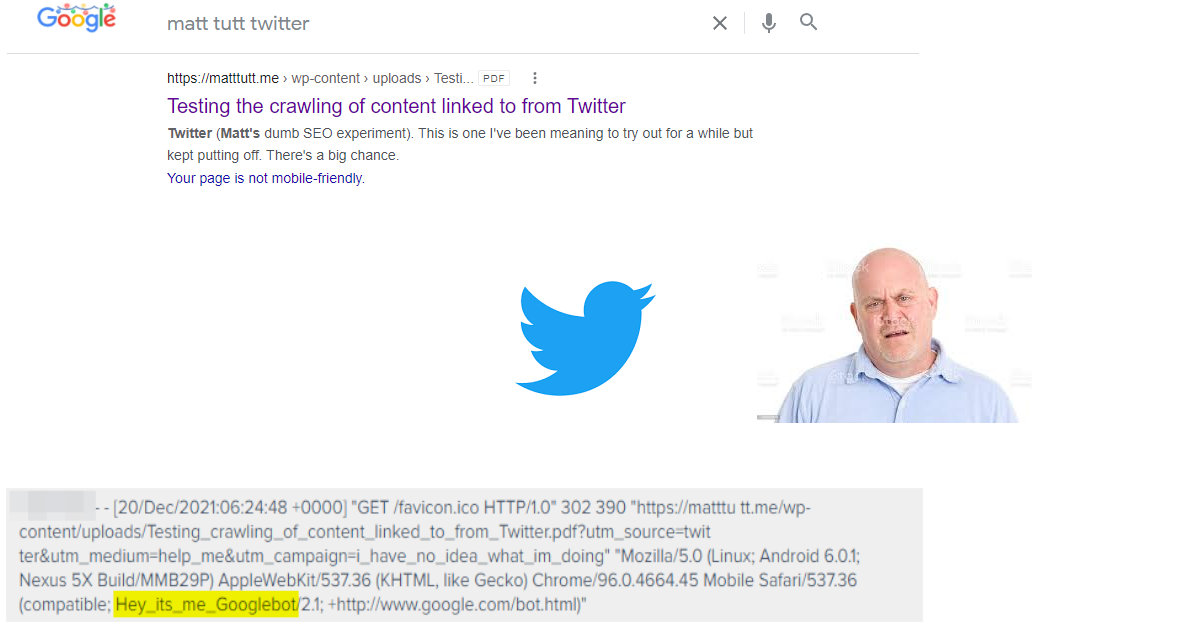
I’ve always been curious about whether Googlebot is crawling or accessing links from Twitter. I think it’s fairly clear that Google does find links from the site, but from my basic research I’ve not really seen much said about the process.
I have seen that Google can feature hashtags in the SERPS as carousels, and can also feature tweets from known entities (just try Googling “your name + twitter” to see what shows up). These have been shown to sometimes result in skewed data within Google Search Console, as Brodie Clark’s nice experiment has shown a while ago.
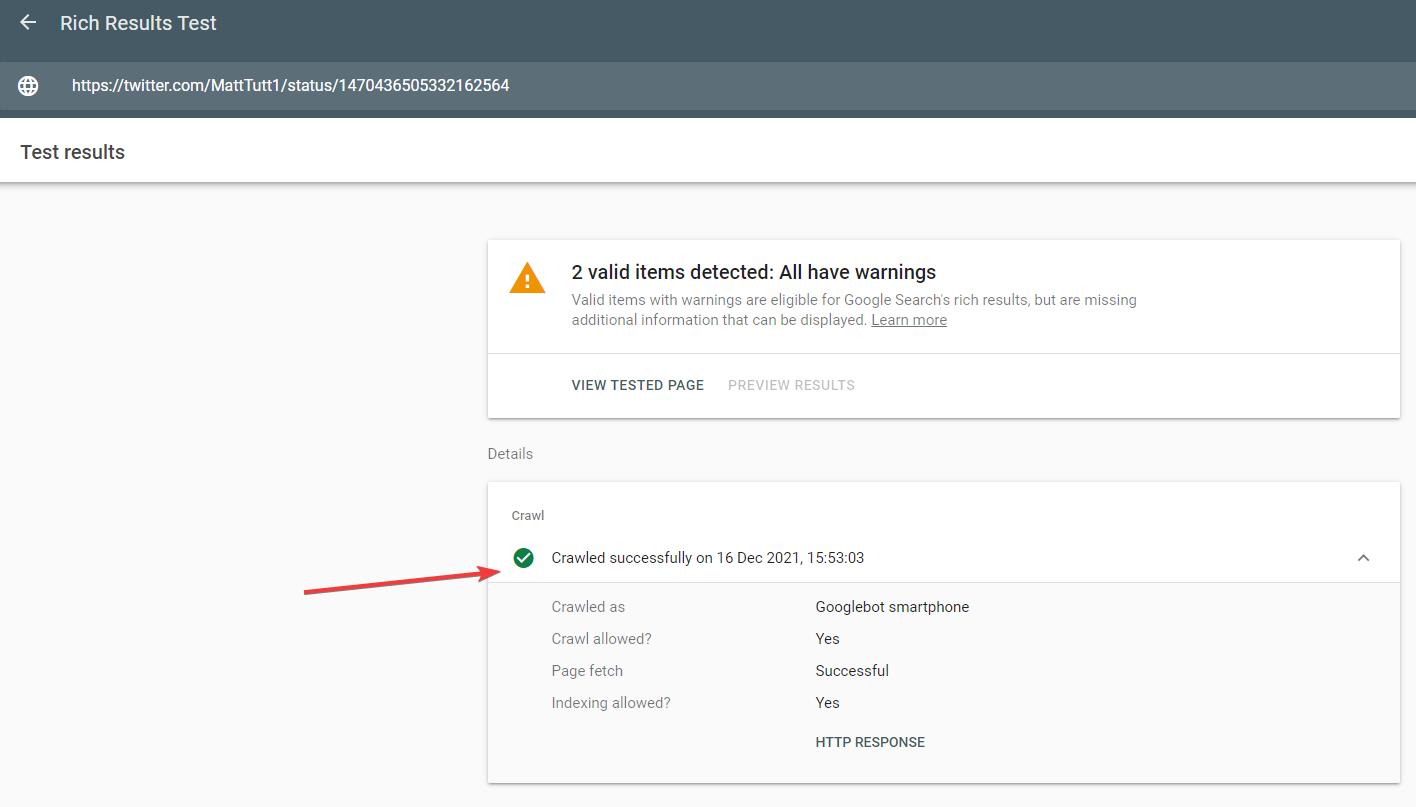
Twitter also has some limitations for Googlebot (and other bots) as shown in their robots.txt file. I could do a super basic test on this again by taking a tweet and checking it’s indexability through the Rich Results Test.
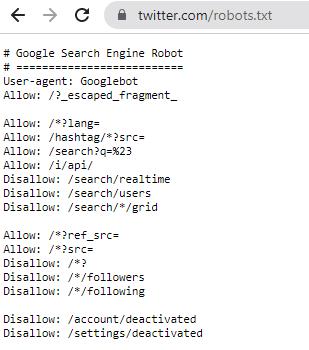
Here we can see tweets are crawlable for Googlebot too.
This is my super simple test in a nutshell:
- I created this document you are reading now (which will be saved as a PDF for super-secret reasons that I’ll announce a few lines down the page).
- I will beg that fellow SEO’s / strangers on Twitter retweet or link to the PDF from a tweet of their own, ideally using a common/relevant hashtag like #seo.
- I will then review server logs and check to see if Googlebot, or other bots, have been able to crawl and access the page URL. My hunch is yes but it will probably depend (it always depends) on whether I can bribe enough people to retweet it 💰
Why are you linking to a PDF - we’re not in the 90’s anymore grandad! 🕰️
Good point, well made. The reason I chose as PDF is thus:
a) I’ve heard Google (or John Mueller?) say that Google would more or less treat a PDF document as another HTML document (emphasis on more or less). I can’t be bothered to find the quote from them on this, as my keyboard is currently broken, sorry.
b) It was the only format I believe WordPress is unlikely to link to automatically, somewhere within the CMS. If I chose a standard Post or Page format it would be included in one of my XML sitemaps by default. There were chances it might get pinged elsewhere upon publishing. I didn’t want to risk it being linked to somehow so figured adding it to the Media Library and not internally linking to it anywhere should be a good rough and ready way to test this.
Obviously this is a critical point - if I link to this PDF somewhere internally, or even if someone else links to it on the web (outside of Twitter) then the whole project will be compromised. There’s a big chance that will happen anyway but let’s see 🔥🔥🔥
Another option here would have been to add a static HTML page to my website, outside of WordPress, to thus avoid any such internal linking. That might have been a better approach as I’m mindful the PDF itself might throw some doubt into the equation. Alas, I haven’t setup an FTP account yet and wanted a quick way to test this…
This feels like something from Inception. What’s wrong with you? 🤓
There’s probably a ton wrong with the experiment but I figured it’d be interesting to find out who/what is crawling stuff on Twitter. I plan on trawling through log files and trying to determine if I can indeed spot anything of interest.
I’ve heard of so many people complaining about Google not indexing their lovely content recently, so I’m curious to learn more about the Discovery process, if at all possible.
Obviously if I don’t spot anything insightful, and nothing does in fact crawl the PDF, then I’ll probably just delete my tweets and we’ll forget all about it. Sounds like a plan? 👍
What do you want us, loyal Twitter follower, to do? 😊
Not a lot - I’ve got further instructions in the tweet I shared, but this is the jist of it:
- Retweet my original tweet.
- Or - write your own tweet, include a link to the PDF file, and again use the #seo hashtag when sharing it.
- Wait a while for the experiment to carry out and for me to write something up on my blog. Note that this may take a very long time as I’m such a busy and important SEO.
📯 Don’t forget - anyone that retweets / tweets a link to the experimental PDF (this doc) will be featured (with a link) in the writeup on my DA 101 blog📯
On the other side of the experiment - so, what happened? 🧪
In summary (so far anyway): not much has happened at all (time of writing this is Friday the 17th).
First things first - obviously the SEO twitter community is great (most times!) and I'm genuinely grateful/shocked at the number of people that got involved and help to spread the word.
I don't consider myself an SEO celebrity (not yet anyway) but I still managed a very respectable number of retweets - 111 at time of writing this (17/12) 👏 thanks again to everyone who got involved!
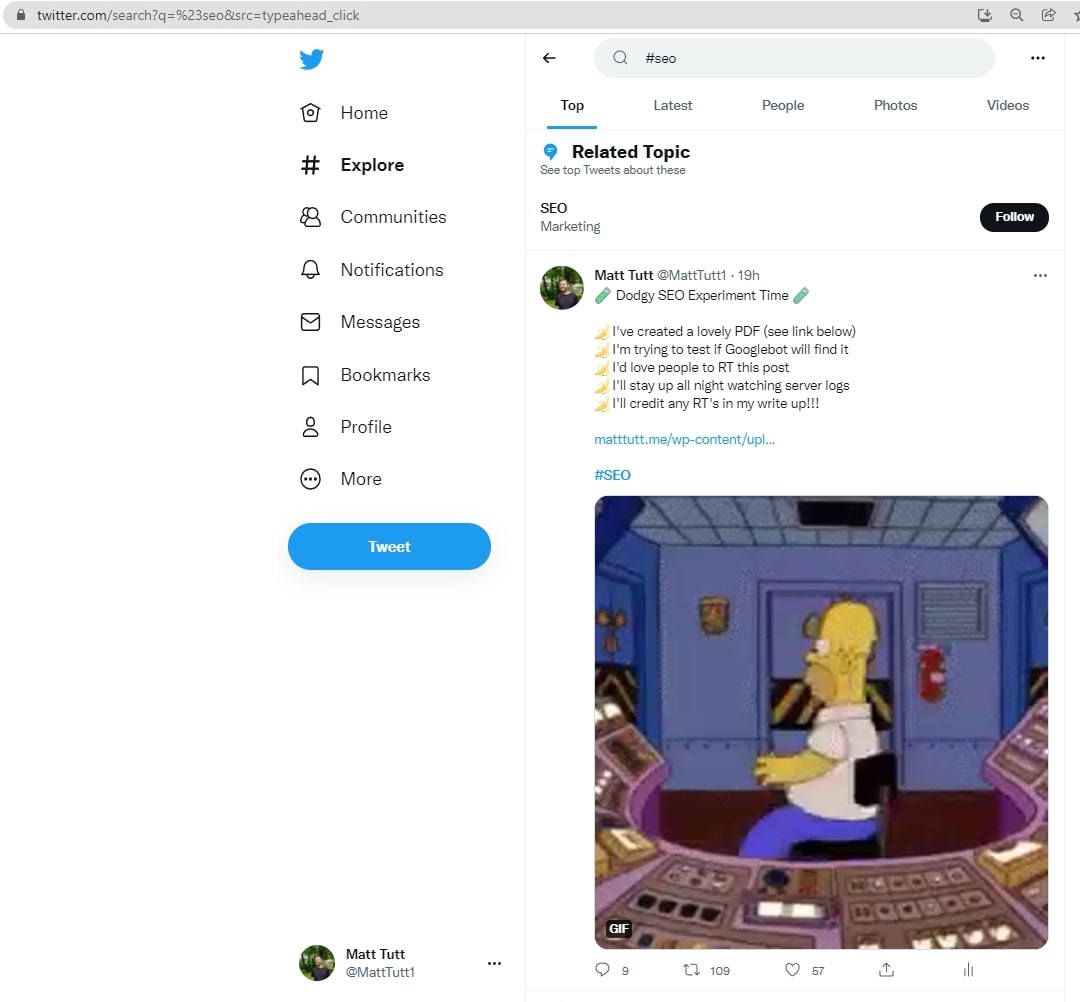
Interestingly I think the tweet did make it onto the #seo hashtag which, according to my calculations, should be accessible to Googlebot (from checking the Twitter robots.txt file) - at this location:
https://twitter.com/hashtag/SEO?src=hashtag_click
I think in this case perhaps it wouldn't have helped with discovery because Google doesn't often surface this hashtag/feed within it's search results. Occasionally it has been known to happen (see the test Brodie Clark linked to above, and the reference to Mordy Oberstein's tweets awhile back).
Initial activity from Server Logs
Honestly I didn't see much bot activity which surprised me somewhat. I caught Twitterbot accessing the PDF a grand total of 1 time, and then a handful of other random bots that I'd not encountered before. But... no Googlebot....
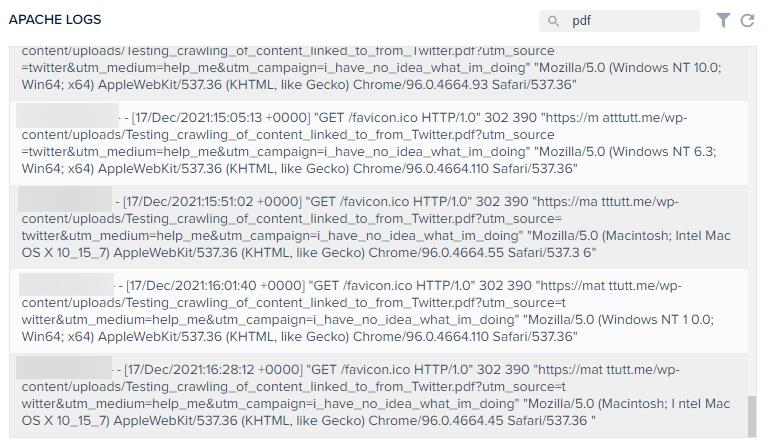
From the above the logs show any visits to the PDF itself during the day. I believe these are from "real" people (take with a pinch of salt perhaps), hence me obscuring any IP addresses shown here.
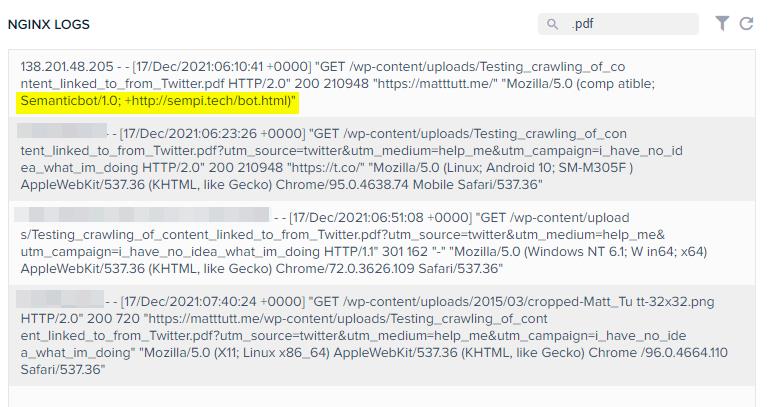
Above shows the NGINX logs which include static resources accessed (such as PNG's, JPG's and PDF's) and here is where I see one bot - Semanticbot/1.0. I couldn't actually find much out about this bot - visiting the URL above takes you to a page which reads "Please contact me at: bot at sempi dot tech." So, not that insightful.
I think there may have been a handful of other bots that don't identify themselves - but either way, still no sign of good old trusty Googlebot.
Soooo basically this was all a big waste of time? 🙄
Potentially yes. But I think it was a fun thing to try out. I might like to tweak some parameters of the test next time.
I did learn from John Mueller that he felt the use of a PDF here WOULDN'T influence things - this was one unknown from my side, whether the use of a PDF may disrupt things.
Personally I'd be curious anyway if using a HTML page would have resulted in more bot activity - perhaps by default they'd not bother to hit a PDF file.
John was also good enough to also confirm that there were several bots that do scrape Twitter hashtags, and that these in itself would warrant my test null and void. Oops. In fairness I don't think John knew this and it sounds like he did his own digging to find that out before hand.
FWIW just a random update since I was curious - it turns out there are various Twitter scrapers (there's even an open-source one that lots use: Nitter), some of them track hashtags. This will likely ruin your experiment.
— 🧀 John 🧀 (@JohnMu) December 17, 2021
Further update - after the dust has settled [Monday 20th]
So there was a bit more to report on today. Funnily enough the PDF has only bloody gone and gotten itself indexed!!! (excuse my language).
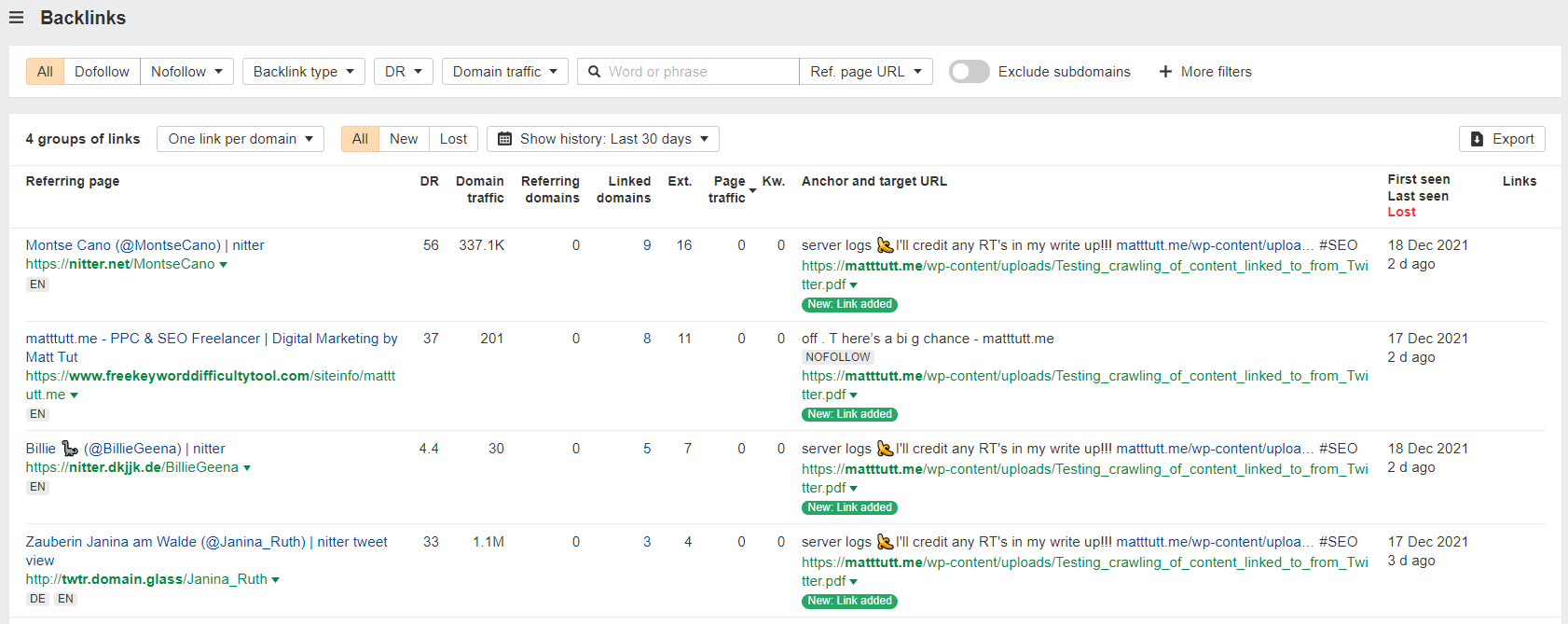
Sadly though as Mr John Mueller had fore-warned earlier on - there are many bad sites out there that just scrape and feature hashtags on their own website. And in this case I was no exception 🎻.
I found a handful of backlinks that point to the T.co shortened URL (Twitter's URL shortener) and to the PDF itself from checking Ahrefs' backlink database.
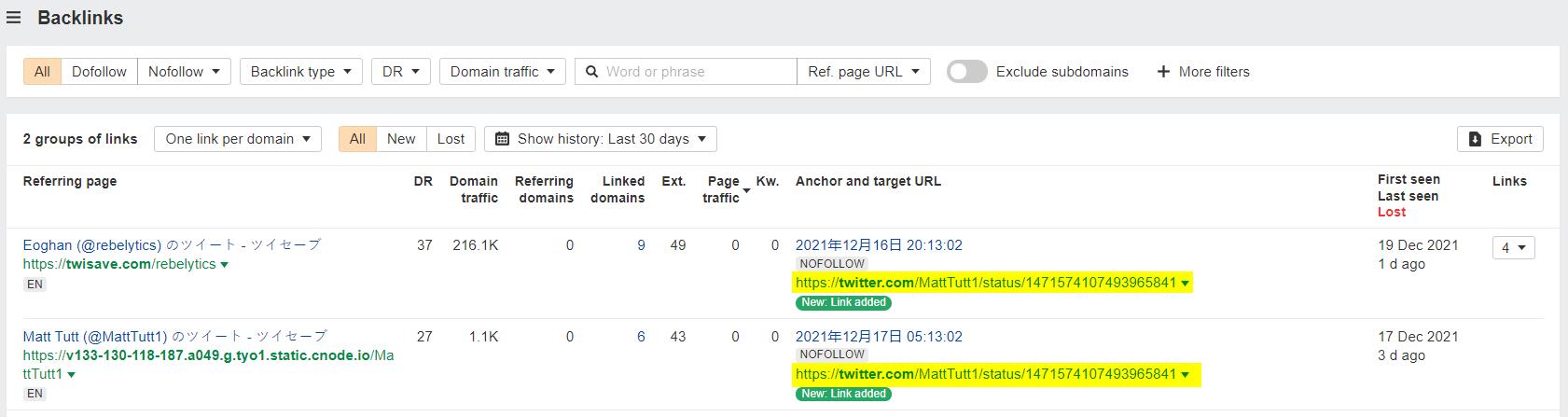
And then I even found links pointing to the tweet itself (kind of weird to think that each tweet is really an indexable URL in itself 🤯)...
So - safe to say this experiment was well and truly flushed down the toilet 🚽.
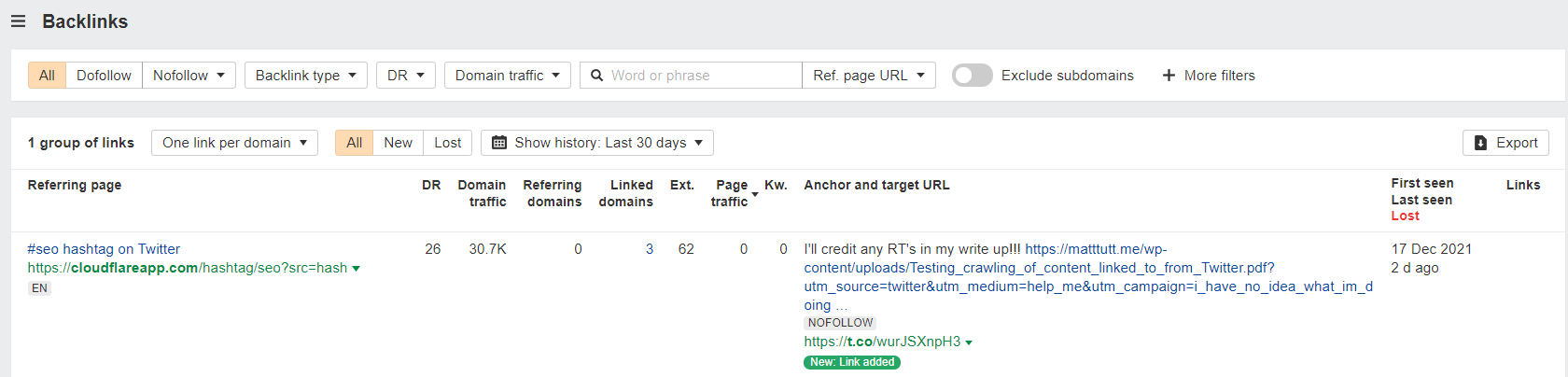
One of the site that scrapes and links heavily is here - https://cloudflareapp.com/hashtag/seo?src=hash
In my browser it shows a page which replicates that of Twitter's - even asking me to login.
I can only see the content on that page if I switch UserAgent to Googlebot / send the request through Google's crawler. Here's a preview of the page from the Rich Results testing tool:
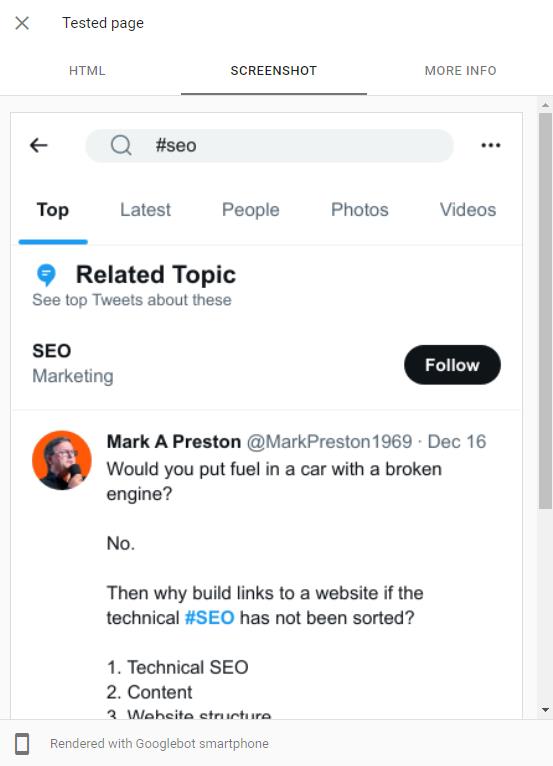
The above is literally just a copy of Twitter from what I can see, so the link to my PDF was likely included as part of my original tweet (the backlink even contains the UTM parameters I'd declared).
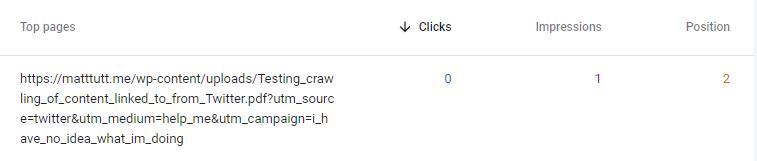
Confirmation of indexing in Search Console
Just to confirm, here is a screenshot from Search Console showing the PDF has been found/indexed. Normally I believe this would be flagged as "indexed but not included in sitemap" but I'm guessing that error might get triggered later (could be too early maybe?) as it definitely isn't in any of my sitemaps.
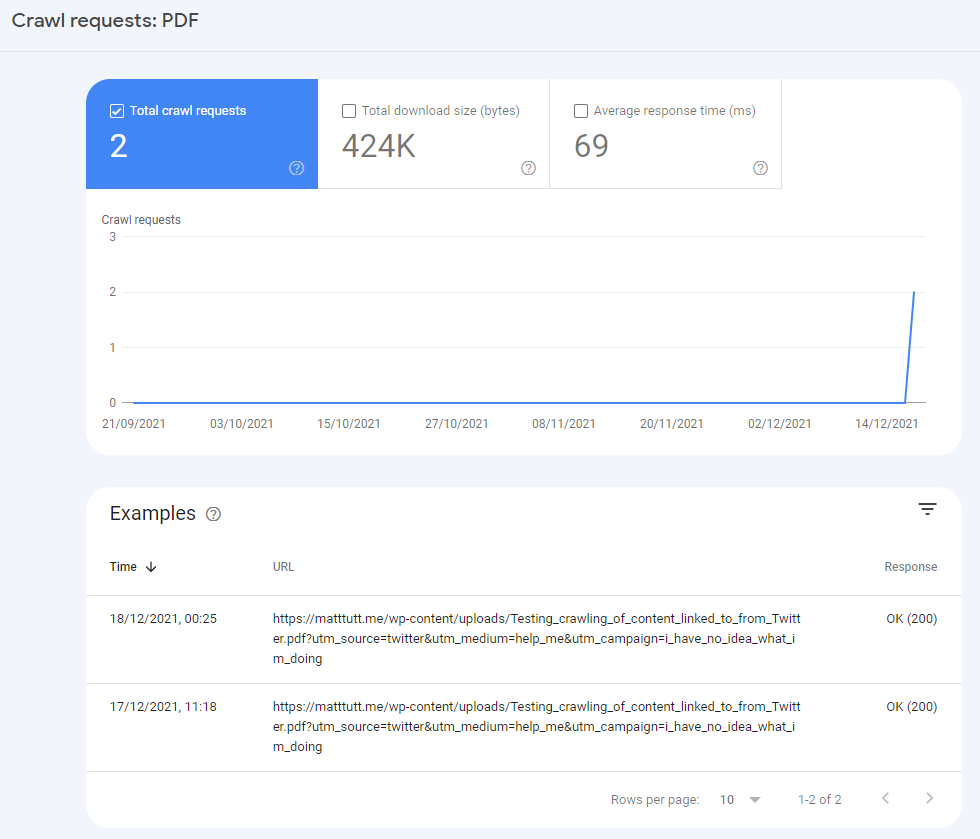
I can also confirm the crawl requests from Googlebot which happened the day after my initial tweet (which I sent on the 16th). I'm a bit lazy technically challenged to find out a way to line up these crawl requests with the time I started to pickup a few scraped backlinks.
But I imagine those links were the reasons for the crawl requests.
Finally, I thought it might be interesting to see the PDF as viewed in the cache (simply to show it looking as a HTML document):
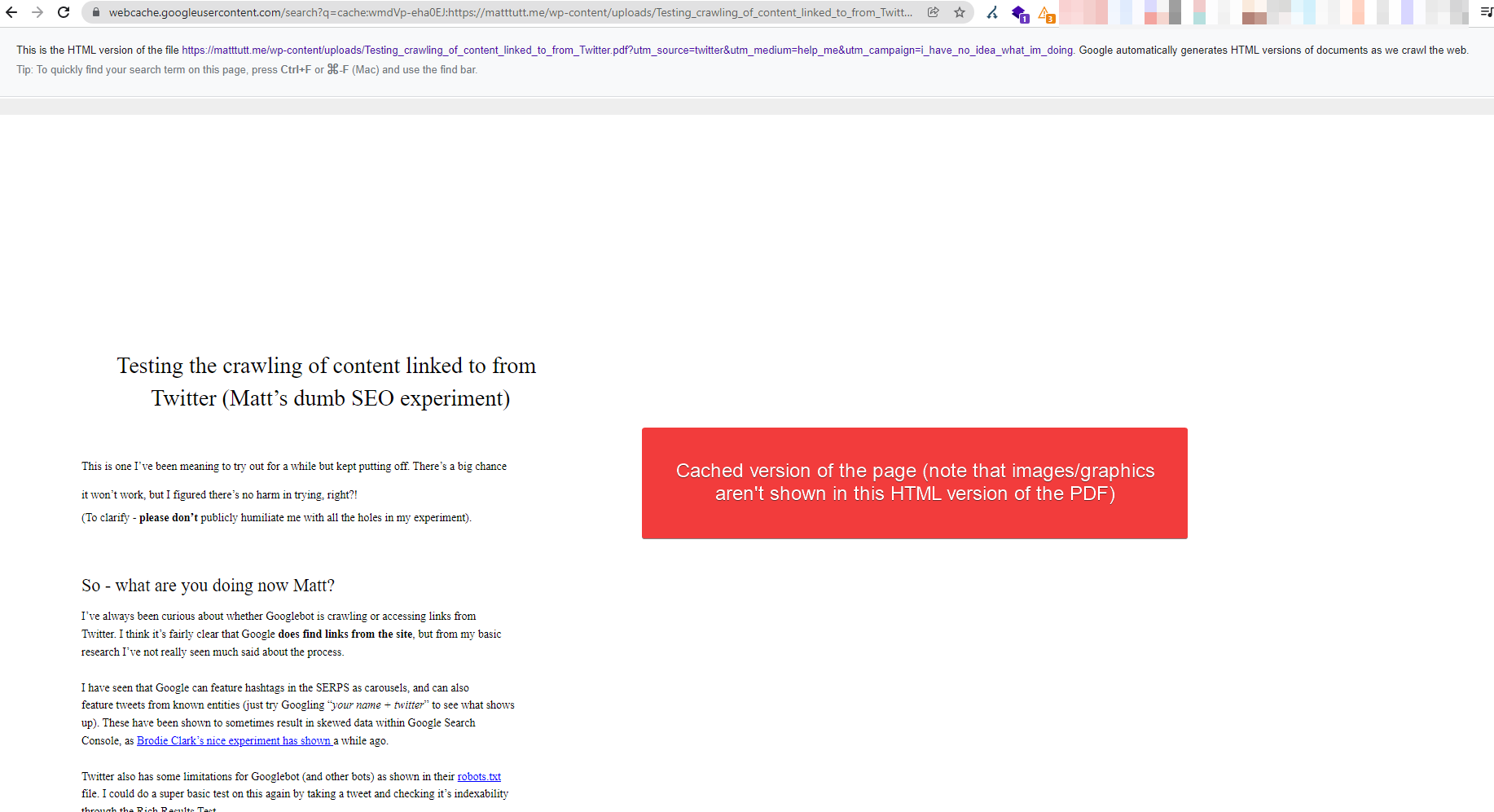
I realise at this point this is all meaningless posturing and drivel - things that get linked tend to get crawled, and sometimes indexed, blah blah blah.
So let's see what else we can learn from this (apart from: I need to get better at compiling and reading my server logs as I still can't find when Googlebot accessed this PDF).

Other Random Musings from Twitter Links
Some things I did find interesting from playing around with this is the use of Twitter's URL shortener service.
When you add link to a tweet it gets shortened to become "https://t.co/" with a random string appended to the end. This then redirects (via a MetaRefresh / JavaScript redirect) to the final end destination, in my case the PDF itself.
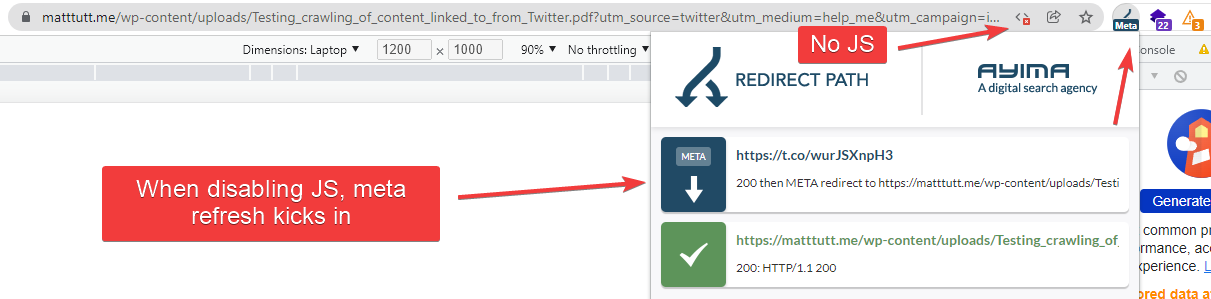
I guess this serves a few purposes for Twitter - saves character spacing in the tweet itself for the user, and it might be an additional security / crawling preservation method.
I doubt Twitter.com wants to link out to so many websites without a means of checking these links for their own security purposes, to protect their users.
Twitter's URL shortener robots file
Checking out the robots file of the shortener service website (https://t.co/robots.txt) we observe a few things.

Google seems to have impunity here, as well as twitterbot, whilst anyone else can... go do one (they're blocked).
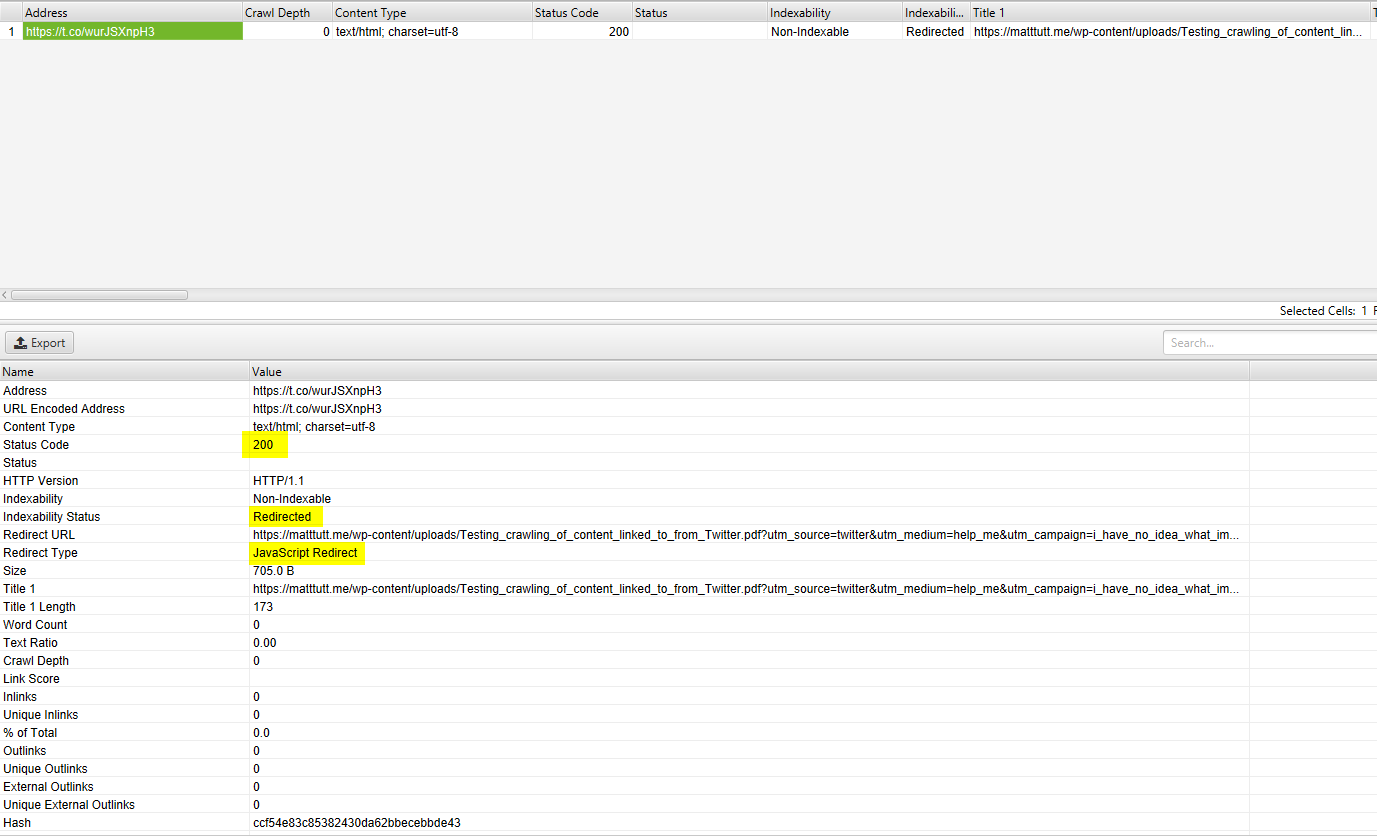
If I was to put through my shortened link in Screaming Frog, with UserAgent set to Googlebot, this is the end result - note this is with JavaScript rendering enabled (I always find the 200 status code / Non-Indexable / Redirected messages a bit of a weird one to get my head around).
And now if I repeat the same test but with Bing as my UserAgent with the same settings as above:
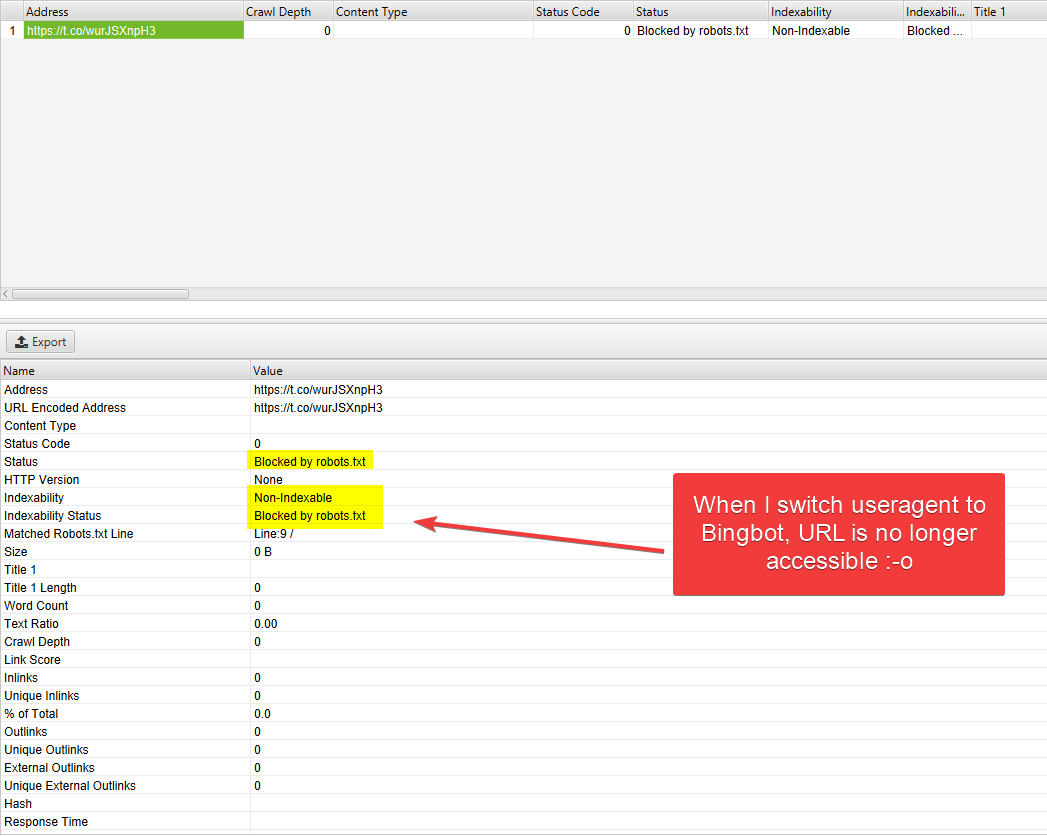
This doesn't mean much in the grand scheme of things, it's just showing the t.co robots.txt file at work.
I think we can prove this is the case by comparing Google's results for t.co pages with Bing's results. Bing does still index them - just with the disclaimer that they couldn't visit them to find/return a meta description and so on.
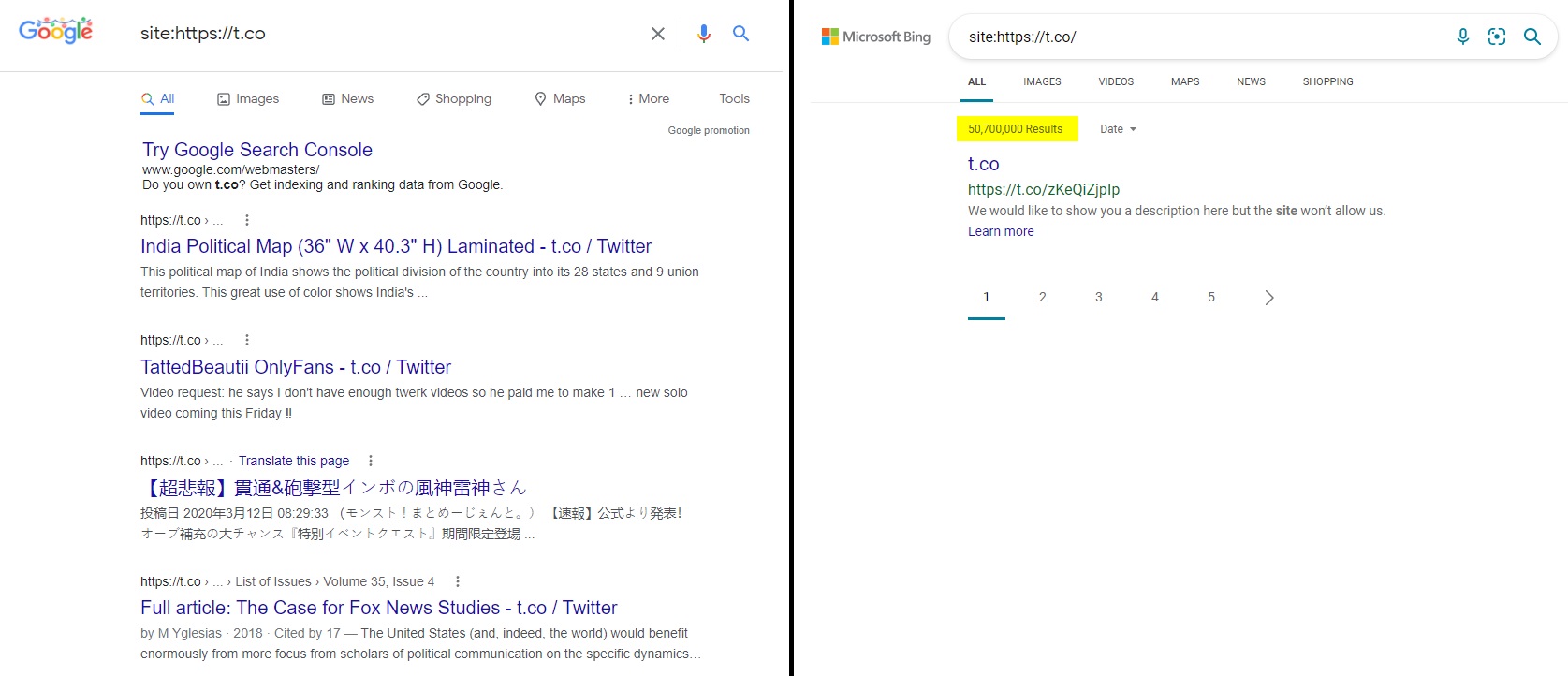
Weird t.co rankings in the SERPs
If we do a very crude indexing check in Google we can see lots of content under the t.co domain. Nothing very competitive here, lots of spam - but looking at Ahrefs' data I wanted to dig a little deeper.
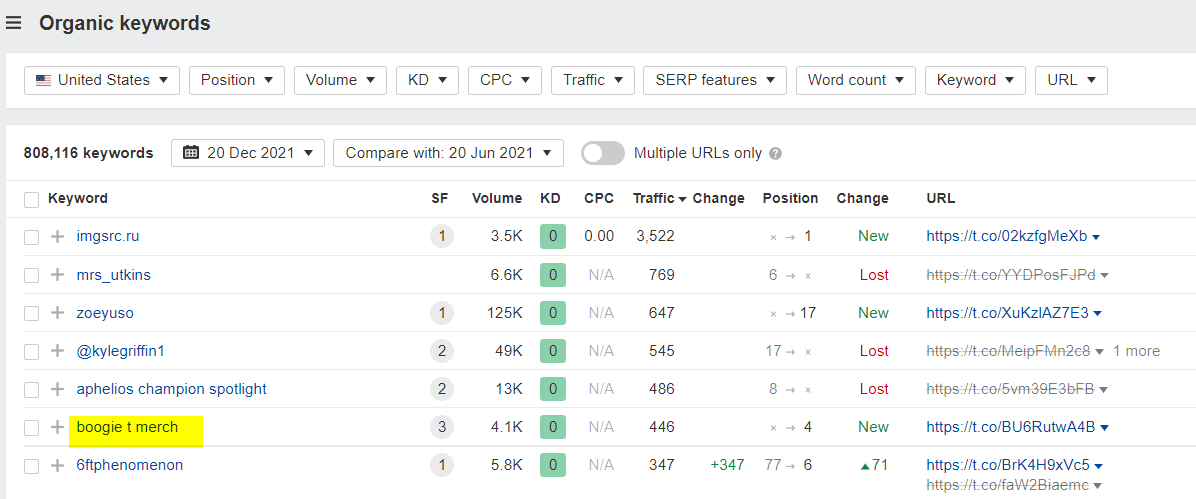
The "boogie t merch" query caught my eye and this led me down a few long and dark, potentially pointless 🐇🕳️.
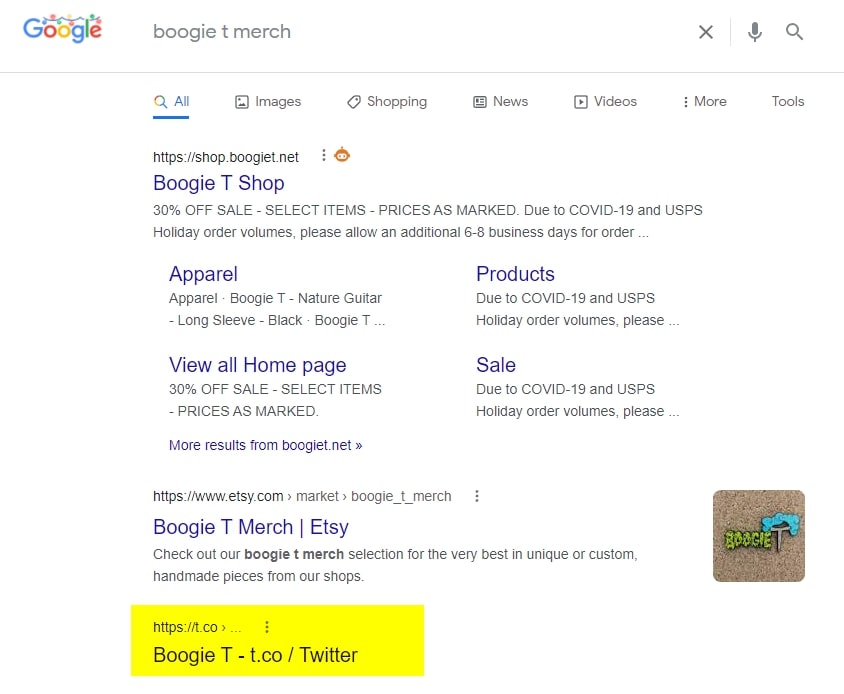
If you were to access the shortened page URL (https://t.co/BU6RutwA4B) you end up on the Boogie T homepage, via a JS redirect after an initial 200 status code.

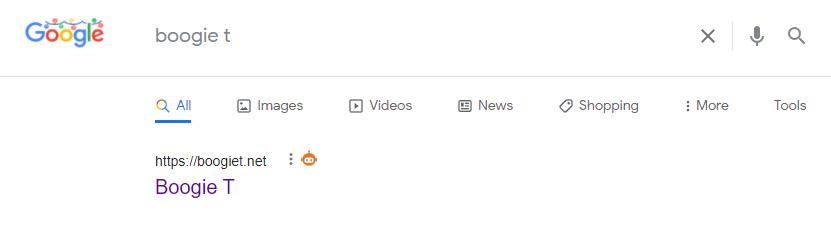
This musician has top spot in Google for "boogie t" with his website (boogiet.net) as you'd expect.
The site seems to be flaky at best; and as such no meta description is shown on Google, and the robots.txt file returns a server error.
Even trying to access the homepage from Google's crawler, I get an error.
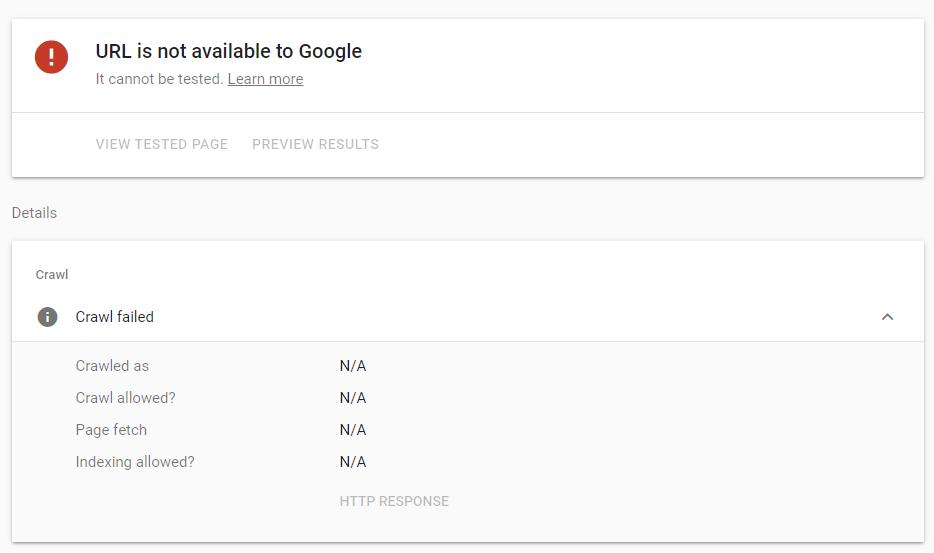
Due to the above issues; I'd guess the T.co URL is believed by Google to be a good/safe result to return, and that the homepage is "stuck" in the index in some way 🤷 (but who cares - not me!!)

Back on topic - takeaways from sharing links on Twitter
I'm not sure if this test showed much to be honest. I wasn't able to clearly identify Googlebot accessing my PDF within server logs. At the same time, the content did get picked up and indexed - so it must have crawled it at some point. In which case maybe I missed it 🤦♂️
Either way, the fact that the tweet itself, the t.co URL shortened version of the PDF link, and the PDF link all received backlinks I think it's safe to say it would have been incredibly difficult to attribute the original tweet and subsequent retweets with any kind of value when it comes to Googlebot's URL discovery.
It's probably worth reading that last paragraph again as it's quite important 👆👆👆.
Want to poke fun at me / give suggestions to the experiment?
Happy to hear your comments below if you have any, or over on Twitter when I re-share this article.
As an FYI I'm also going to 301 the PDF from this experiment to this new post. I did consider doing another test here, by publishing the write up on a static HTML page outside of my WordPress installation, but then I figured I'd end up stuck in some kind of existential loop and the experiment may go on-and-on and-on.... a little like this article 😅.
Supporters of this Experiment
Because I'm a man of my word (sometimes) here are all the wonderful people who retweeted or shared my original tweet, without which I'd be a very sad, lonely little person.