I was running some tests recently to see what additional information can be obtained about Googlebot, with regards how it fetches and renders content on a webpage. Personally I'm invested in this area as many clients I work with are making use of Javascript to render content, and it was an area I wanted to look at further to help my own understanding of the fetch, render and indexing process. With Javascript Google is improving it's ability to understand several key Javascript frameworks, which in turn should give websites using that technology a better organic search performance. But Google (and particularly John Mueller) have been keen to stress that they're still a long way off being perfect, and they recommend that SEO's and web developers take time to understand the issues that Javascript can cause on a website.
Lots has been written about this particular area recently by many far more proficient SEO's than myself - Bartosz and his team at Elephate have made great progress at establishing themselves as real Javascript SEO specialists, whilst Barry Adams at the State of Digital put together a great resource about Javascript SEO a few weeks ago too. I wanted to run some of my own tests to see what else I could discover, if anything, about Googlebot (and when referring to Googlebot I'm actually talking about Google's Web Rendering Service (WRS), and less about Google Caffeine, the bot responsible for indexing content, although it's obviously important to know their relationship).
I thought it'd be interesting to know what, if anything, can be gained by analysing Google Analytics data when combined with fetch and renders within Search Console - are we able to track Googlebot?...
What we already know about Googlebot
So far in 2018 various pieces of information have been gathered to paint a particular picture of Googlebot. I've included the key points below, which by now I think are pretty much agreed in the world of SEO:
- Googlebot is based upon Google Chrome browser version 41. If you wanted to test how Google renders your Javascript content, it's a good idea to download this version (which is several years old already) to see a pretty good example of how Google renders your site in the DOM - which should be more accurate than using Fetch and Render in Search Console.
- Googlebot typically only hangs around for about 5 seconds when accessing a page - so any Javascript/other content and scripts needs to load in the DOM by that time or it's missed.
- Googlebot doesn't "click around" when accessing your site - if you use a navigation menu with "onclick" JS functionality for example, Google may not find the other pages you link to (so it's recommended to use ahref linking methods to be safe).
- Googlebot doesn't like URL's with hashtag characters in them (which many JS frameworks use, such as Angular v1); so using these is not recommended (hashbang URL's might be OK though).
- Googlebot tries to detect whether content has to be rendered before doing so as it's wasteful for them to render everything they find on the web.
As recommended by Google here, if you have problems understanding how they're rendering your content you should first use Fetch & Render within Search Console itself, followed by logging any errors from the Javascript execution. Note that fetch and render is just a theoretical output as to how the page should appear for Google, and although viewing the site's cached content in Google is another option, it won't help much as the cache uses your own browser to output any code encountered.
Testing Fetch & Render with Google Analytics
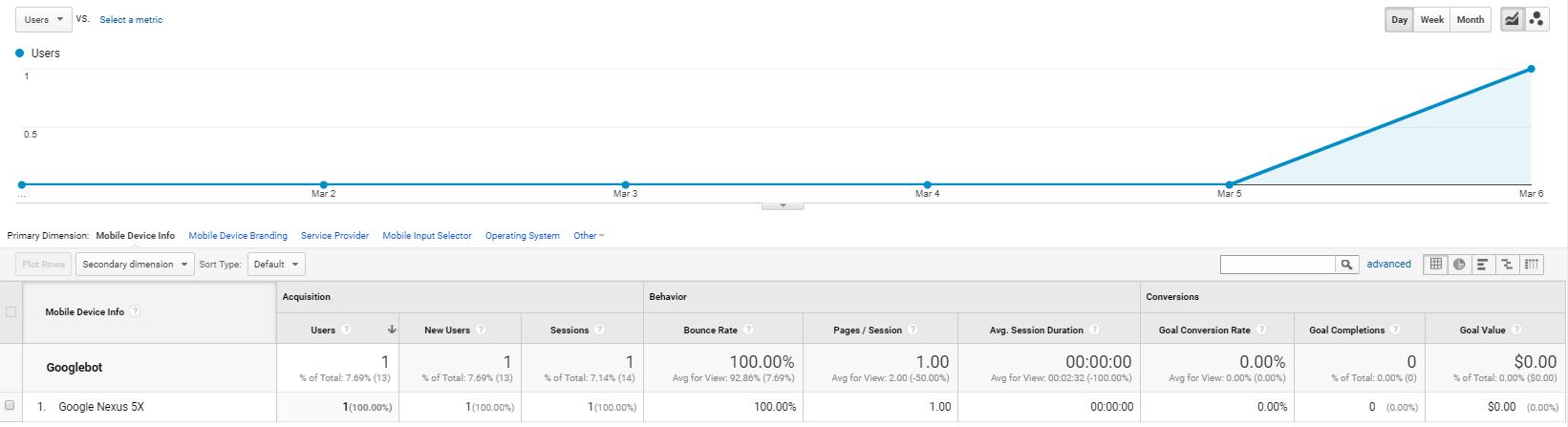
I wanted to see what happened when I tried accessing my real-time Google Analytics report during a Fetch and Render request within Google Search Console on a website I'd only just created, which had Google Tag Manager/Analytics script added. I'd assumed that nothing would've happened - that no sessions would've been created within Analytics because it wasn't a "real" visit (I realise many spam bots exist, and scripts which spoof UA script sessions, but I figured Google would've been different). To my surprise they were tracked - each fetch and render created 2 sessions. Here's what I found out:
- Googlebot was accessing the site from the US (as was expected), although the site is based/hosted in Europe and Google has many datacenters. Further specific location info wasn't supplied within GA.
- 2 Active Users were tracked during the fetch & render. 1 user was tracked for just a fetch.
- Session time appeared indefinite, or until a new fetch & render was requested.
- Hostname traffic was originating from Google LLC (more or less confirming it was Google).
- Approximately 50% of sessions were using Google Chrome browser, the rest were "not set".
- The specific version of Google Chrome was 41.0.2272.118 (confirming what we knew already).
- Linux operating system were 50% of sessions too (using Chrome browser), the rest were "not set".
- All sessions were using a Screen Resolution of 1024 x 768.
- When doing a fetch & render as Mobile: Smartphone, 1 mobile and 1 desktop session were tracked.
- The mobile device used here by Google is a Google Nexus 5X (big surprise!).
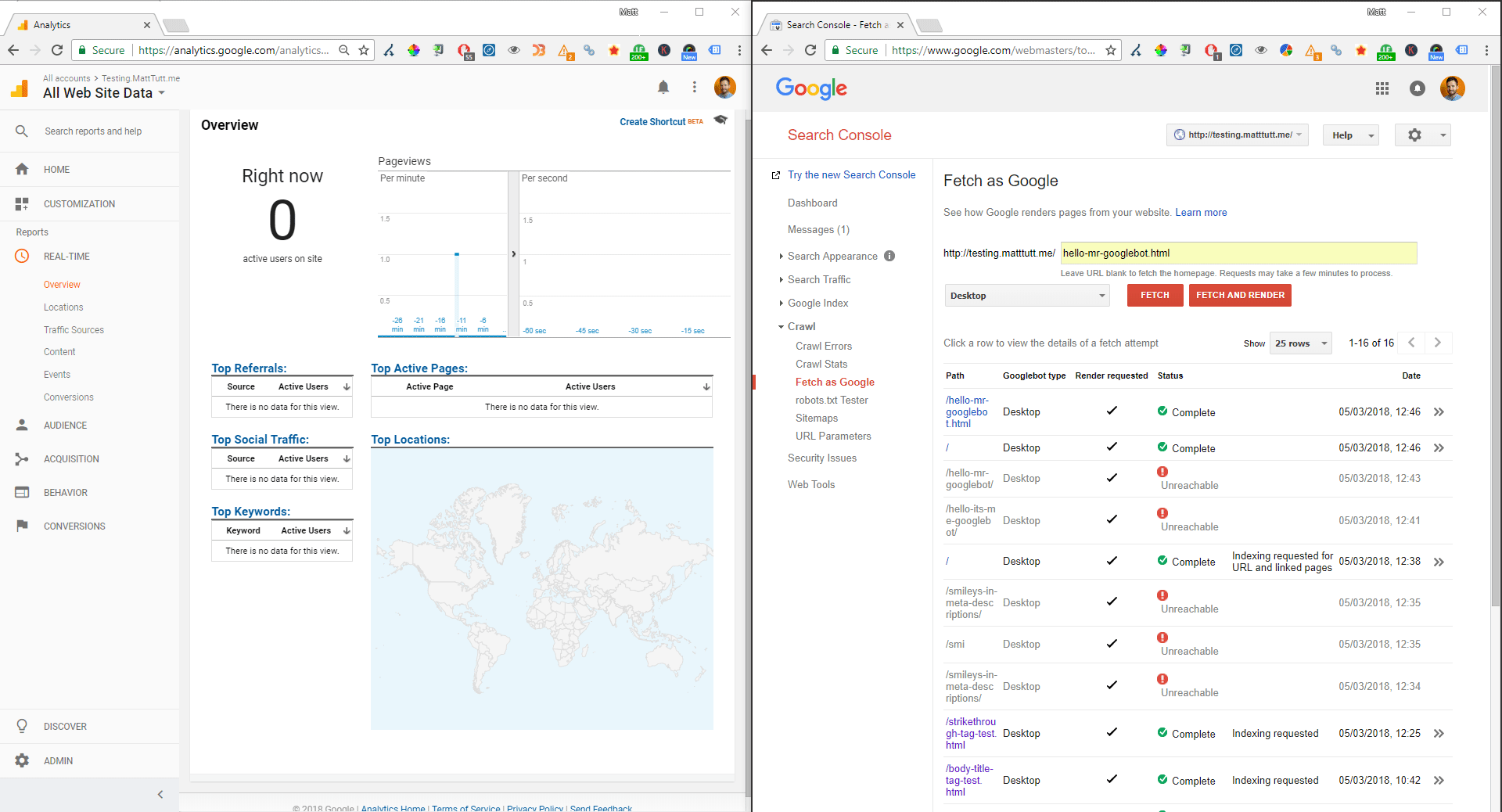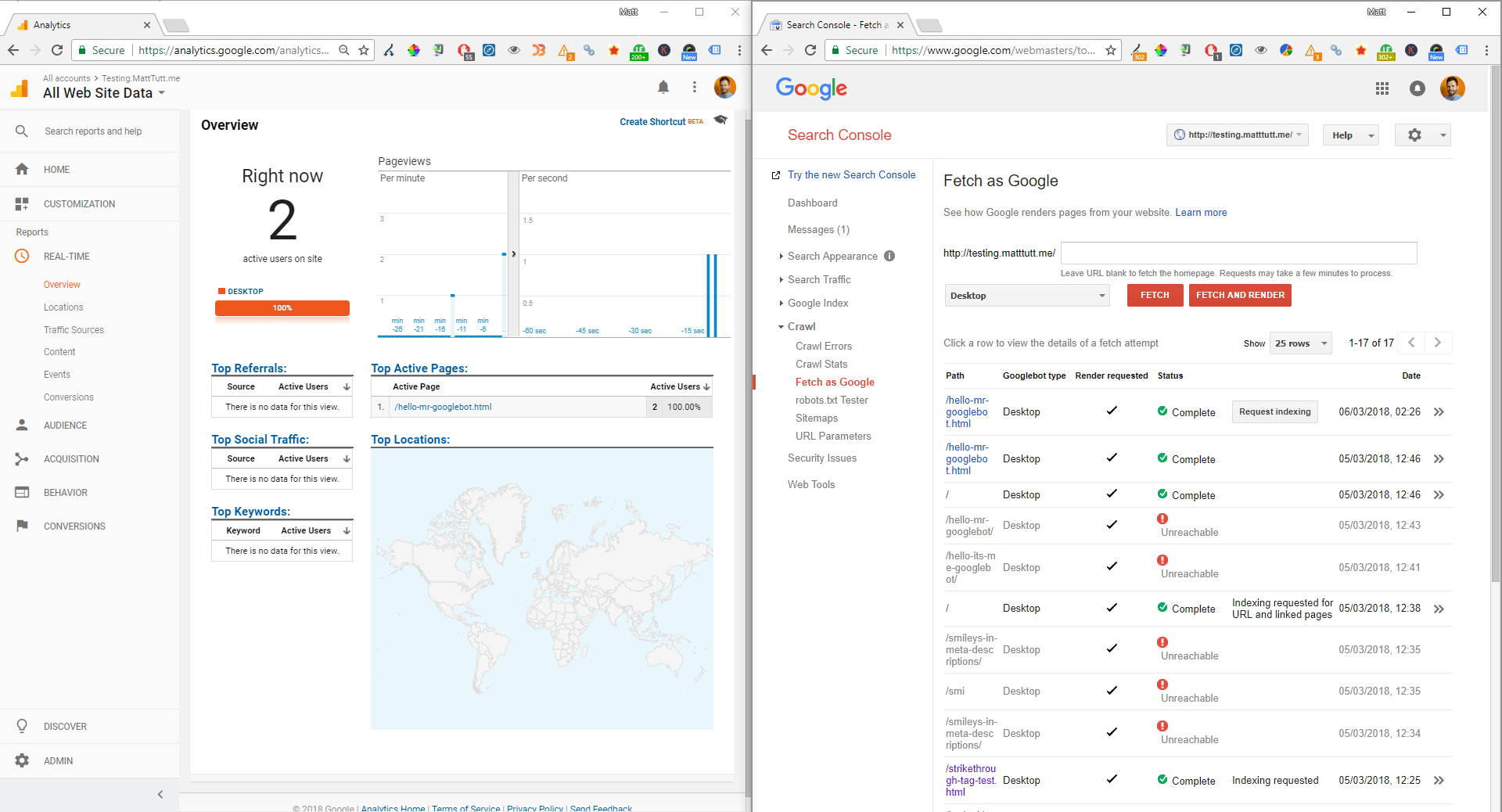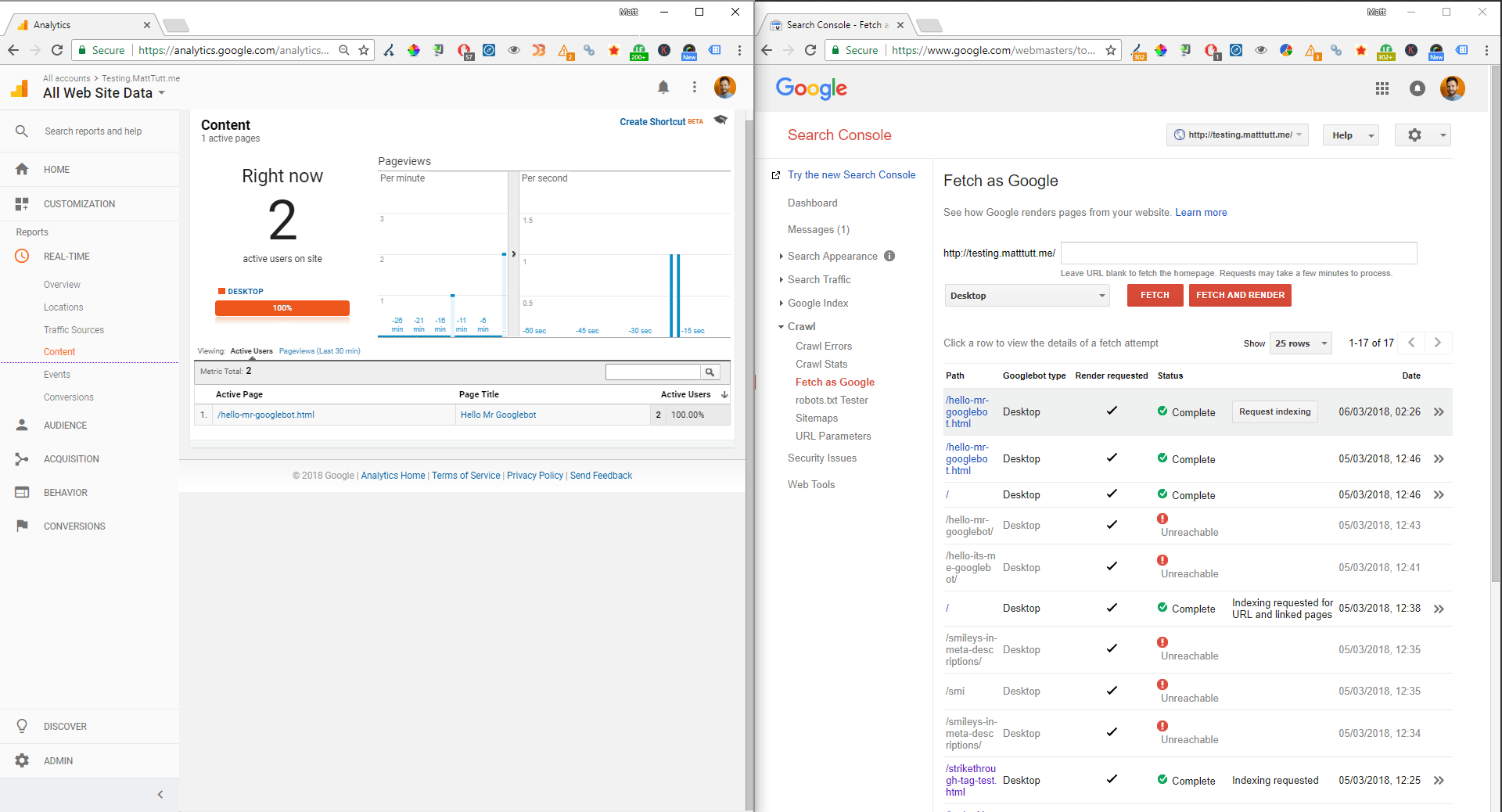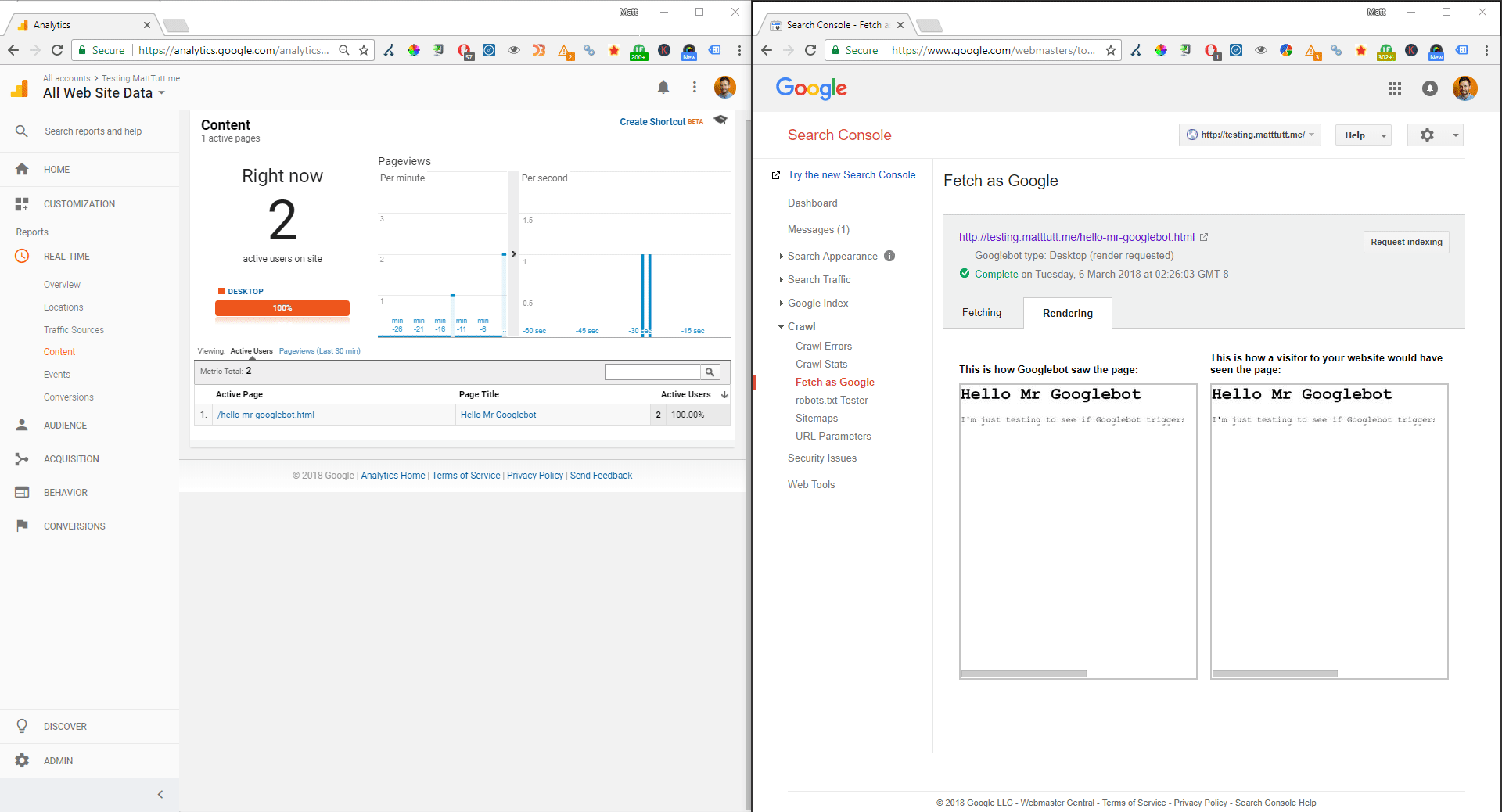
Screen recording of the fetch and render / Real-time Analytics report
There's nothing new or insightful with the above findings, it just matches up with what others have said previously (such as JR Oakes' great piece on hacking the Search Console log)
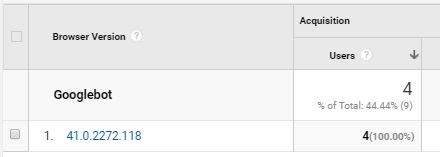
Confirming the version of Chrome used by Googlebot (note that "Googlebot" text above is a custom segment I created in Google Analytics).
Other things to note are again the Google Chrome browser version for desktop (41.0.2272.118) whilst for the Mobile crawler it's a Google Nexus 5X. So using Google dev tools as a Nexus 5x, from Chrome 41 browser should be a good way to emulate how Googlebot for mobile really sees your website's mobile version.
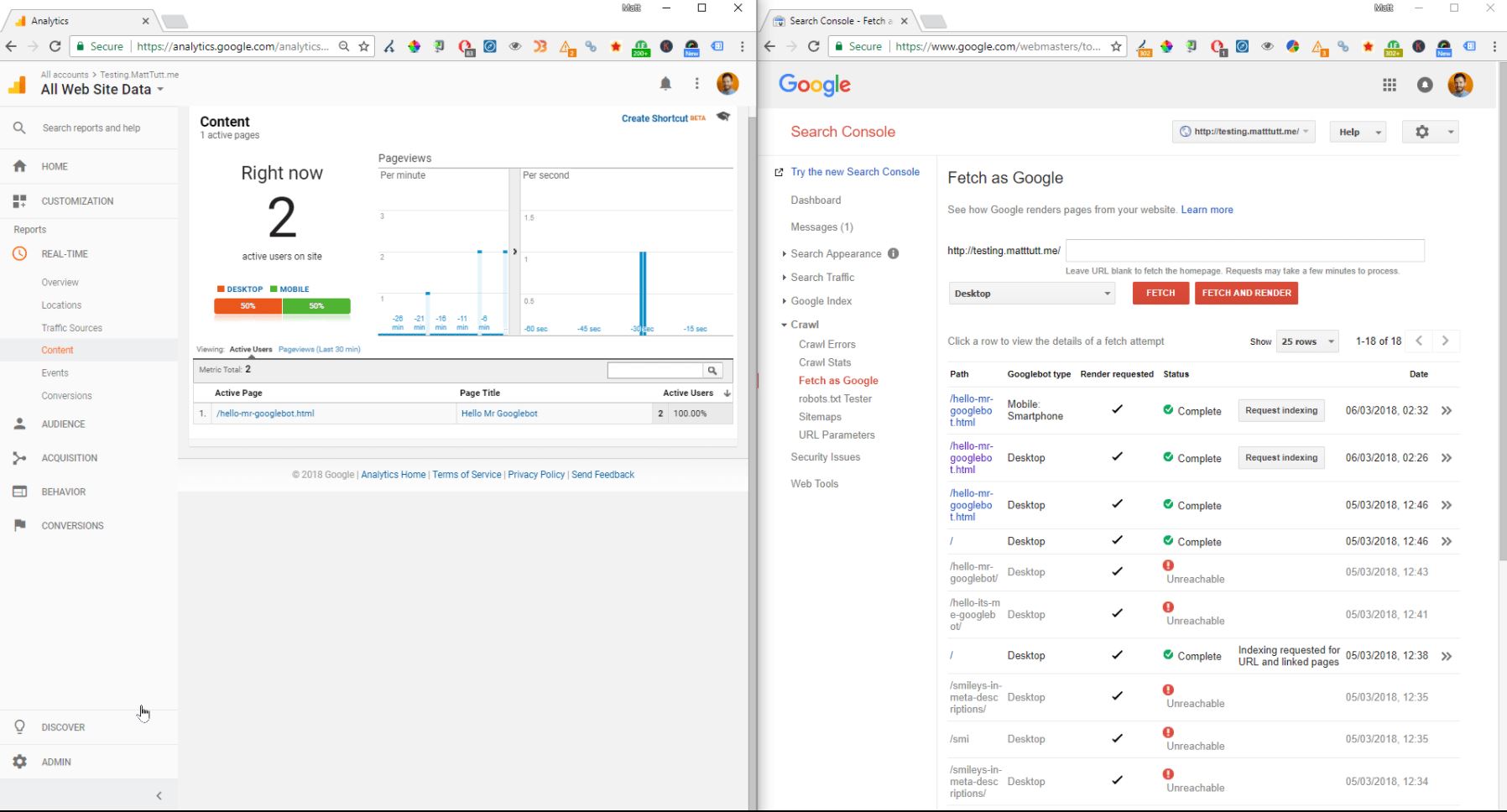
Screenshot showing the Mobile fetch and render request
Taking this further?
I realise all the above is relatively easily available within a site's server logs, but to me it's interesting to see that this information was also very easily accessible within Google Analytics. It also confirmed the version of Chrome browser used to access sites, as well as the mobile version used by Googlebot. Many SEO's are keen to know if/when Google will start using a more modern version of Chrome to render their websites, and this could be one way to test this out as we move closer towards the mobile-first index (useful to those who can't access server logs either) - but that depends on whether the fetch and render feature will match that as used by Google's real WRS.